EvalLM ⚗️ is an interactive system that aids prompt designers in iterating on prompts by evaluating and comparing generated outputs on user-defined criteria. With the aid of an LLM-based evaluation assistant, the user can iteratively evolve criteria+prompts to distinguish more specific qualities in outputs and then improve the quality of outputs on these aspects.

The main screen of the interface consists of three panels.
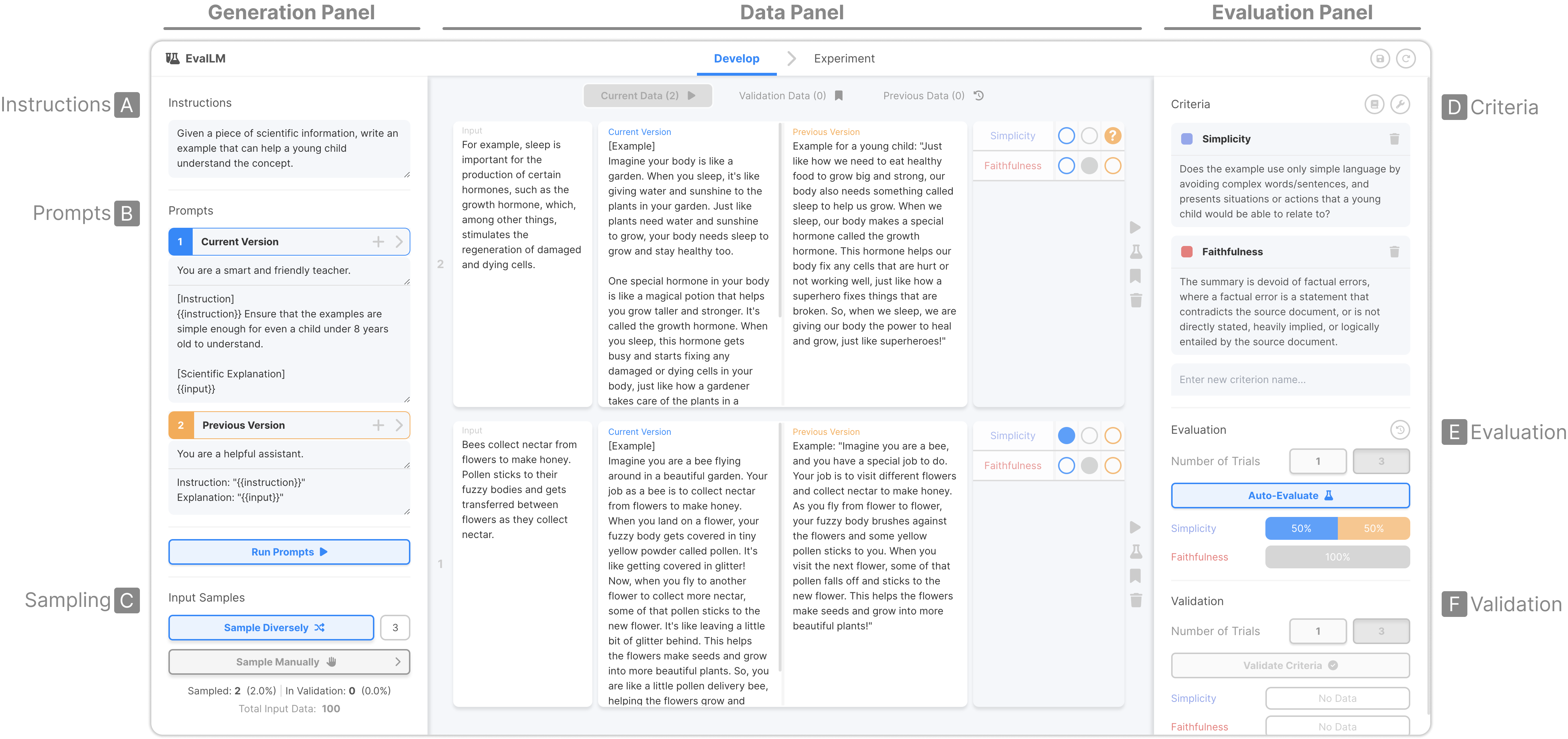
Generation Panel: To generate outputs, the user defines their overall task instruction (A), two prompts they want to compare (B), and then samples inputs from a dataset (C) which will be used to test the prompts.
Evaluation Panel: To evaluate outputs, the user defines a set of evaluation criteria (D). Then, after evaluating, they can verify the overall evaluation performance of each prompt (E) or, if they created a validation set, validate how automatic evaluations align with ground-truth evaluations (F).
Data Panel: This panel shows data rows containing inputs, outputs, and evaluation results.
EvalLM allows users to evaluate outputs on their own criteria specific to their application and/or context.
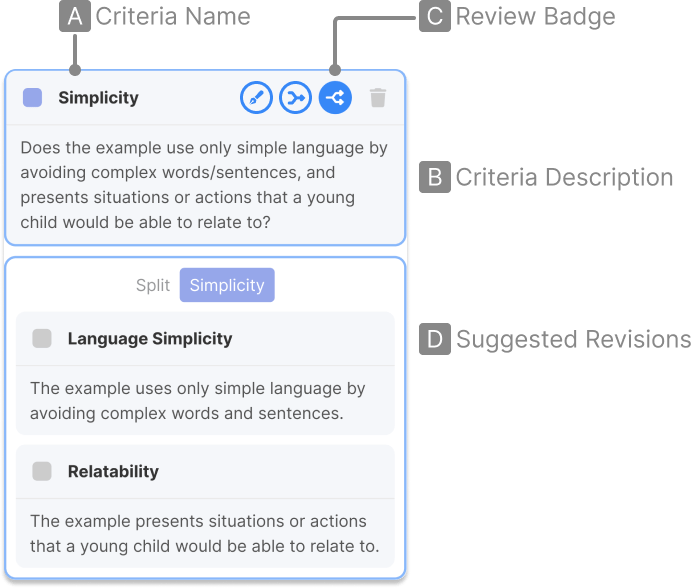
To define a criteria, the user simply provides the criteria with a name (A) and description (B) in natural language.
To assist users in creating more effective and helpful criteria, the system automatically reviews their criteria (C) and provides suggestions (D) on how the criteria can be refined, merged and split.

For each sampled input (A), the interface presents the outputs generated from each prompt side-by-side (B) and the evaluation results for each criteria next to the outputs (C). For each criteria, the evaluation results show which prompt produced the output that better satisfied that criteria.
If the user wants to see more details, they can click on one of these evaluations to see the assistant’s explanation (D). To help the user match the explanation and outputs, the system also highlights spans from the outputs that were considered to be important when evaluating the criteria (E).
If the user selected to evaluate outputs on multiple trials, they can see the evaluations for other trials through the carousel (F).
See EvalLM in action in this Video Demo.
@inproceedings{10.1145/3613904.3642216,
author = {Kim, Tae Soo and Lee, Yoonjoo and Shin, Jamin and Kim, Young-Ho and Kim, Juho},
title = {EvalLM: Interactive Evaluation of Large Language Model Prompts on User-Defined Criteria},
year = {2024},
isbn = {9798400703300},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3613904.3642216},
doi = {10.1145/3613904.3642216},
booktitle = {Proceedings of the CHI Conference on Human Factors in Computing Systems},
articleno = {306},
numpages = {21},
keywords = {Evaluation, Human-AI Interaction, Large Language Models, Natural Language Generation},
location = {, Honolulu , HI , USA , },
series = {CHI '24}
}
![]()
![]()
![]()
This research was supported by the KAIST-NAVER Hypercreative AI Center.




